")

")
")
Vấn đề Split-Brain nghiêm trọng trong Elasticsearch Cluster – Cuongquach.com | Chúng ta sẽ cùng đến với một vấn đề rất quan trọng cần chú ý khi thiết kế hệ thống Elasticsearch Cluster, đó chính là ‘Split-Brain‘ . Split-Brain là gì ? Liên quan đến thành phần nào trong hệ thống ES Cluster? Hãy cùng tìm hiểu với Cuongquach.com nhé.
Trước khi bạn đến với bài viết này, cần đọc bài khác về vai trò Master Node : Tổng quan về Master Node trong Elasticsearch Cluster
Có thể bạn cũng quan tâm chủ đề khác
– Những lưu ý thường gặp khi sử dụng Filebeat gửi log
– Tạo Document cơ bản trong Elasticsearch
– Tạo Index cơ bản trong Elasticsearch
– Tìm hiểu Logstash trong ELK
Contents
Vấn đề ‘Split-brain’ trong Elasticsearch Cluster
Các bạn đã nắm được vai trò quan trọng của ES Master Node trong cụm phân tán Elasticsearch Cluster. Thì hẳn bạn phải luôn luôn nghĩ đến việc nếu chỉ có 1 con Master Node thì sẽ rất nguy hiểm, nên thường nhiều người mới sẽ cấu hình thêm 1 Master-eligible Node sẵn sàng. Như vậy chỉ có 2 Master-eligible Node với cấu hình mặc định ban đầu của Elasticsearch sẽ phát sinh một vấn đề rất nghiêm trọng mang tên ‘Split-Brain‘ trong một ES Cluster. Cùng phân tích nhé.
Giả định kịch bản
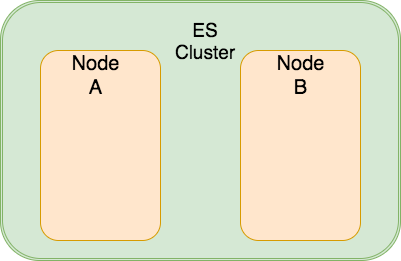
Ta có một cụm ES Cluster với 2 máy chủ ES Node. Cả 2 vừa là Master-Eligible Node và Data Node.
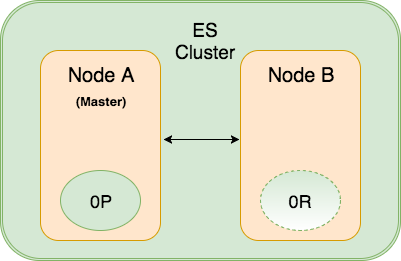
ES Cluster này đang lưu 1 Index với 1 Primary Shard và 1 Replica. Node A được bầu chọn là Master Node trong cụm này và giữ Primary Shard (kí hiệu là 0P), còn Node B giữ Replica Shard (kí hiệu là 0R).
Chẳng may một hôm nọ, sự cố phát sinh về đường mạng (không tính vấn đề một hệ thống sự cố downtime) giữa 2 Node A và B. Cả 2 Node thật chất đều vẫn còn đang chạy vù vù, nhưng cả hai không thể giao tiếp kiểm tra lẫn nhau qua hình thức ping (zen discovery).
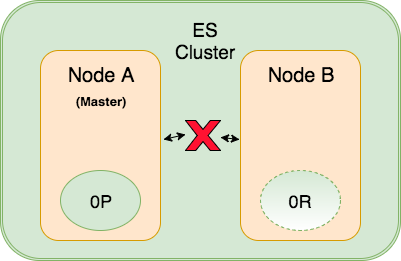
Cả Node A và Node B đều tin rằng Node kìa đang có vấn đề như đang downtime chẳng hạn. Node A sẽ chẳng hành động gì mới, vì bản thân nó đã là Master Node hiện hành. Nhưng Node B thì lập tức tự động bầu chọn chính nó làm Master Node mới vì nó tin rằng phần còn lại trong Cluster hiện không còn ai làm Master.
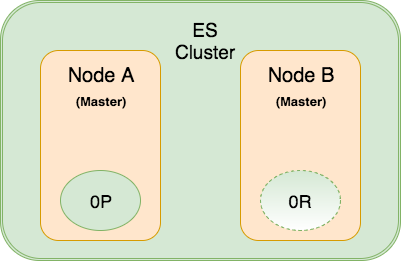
Và như bạn đã biết thì nhiệm vụ của một Master Node trong ES Cluster, đó là quản lý các shard của Index giữa các Node. Lúc này Node B đang giữ một Replica Shard của Index và tin rằng không còn Primary Shard nào tồn tại nữa, vì vậy mà Node B Master Node tự chuyển Replica Shard thành Primary Shard.
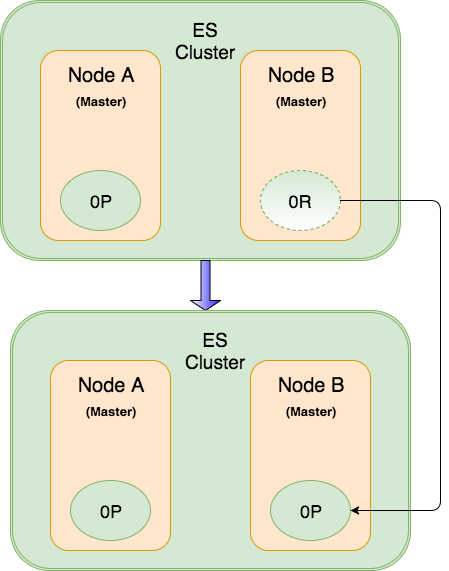
Lúc này Node A và Node B trở thành 2 Master Node độc lập, như ta biết 1 ES Cluster chỉ có 1 Master Node duy nhất chạy 1 thời điểm. Nên 2 Master Node độc lập cùng chạy sẽ trở thành 2 ES Cluster độc lập , quá trình này được gọi là ‘Split-Brain‘. Lúc này dẫu đường truyền mạng có khôi phục lại thì cũng không khôi phục được trạng thái Master Node ban đầu, trừ khi cả 2 node cùng khởi động lại dịch vụ Elasticsearch để bầu chọn lại Master Node.
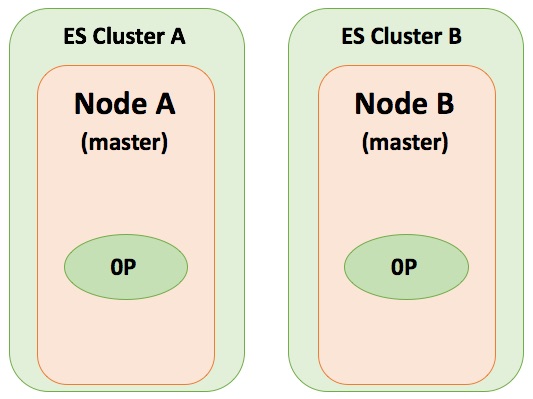
Lúc này hệ thống ES Cluster của chúng ta bắt đầu phát sinh sự cố về trạng thái của các Node không còn chính xác. Tình huống vấn đề sẽ phát sinh khi mà các Index request nếu xuống Node A thì Node A tự ghi vào primary shard của nó, nếu Index request xuống Node B thì Node B tự xử lý với primary shard của nó và hoàn toàn không có cơ chế dự phòng replica shard nữa.
Tình huống này rất khó phát hiện, chỉ đến khi bạn query Index và thấy thiếu kết quả trả về so với mong đợi.
Ảnh hưởng của vấn đề ‘Split-Brain’
Nếu hệ thống phân tán Elasticsearch Cluster bị dính trường hợp ‘Split-brain‘ thì toàn bộ cụm phân tán Elasticsearch Cluster của bạn sẽ rơi vào tình trạng đáng báo động có khả năng mất dữ liệu rất nặng khi không còn Replica Shard. Bởi vì Master Node quản lý phân tán dữ liệu liên quan đến Index, Shard,… nên nếu bị phân tán không tập trung vì có 2 Master Node cùng lúc, thì tính dự phòng của dữ liệu sẽ tan tành.
Xử lý Split-Brain như thế nào ?
Để xử lý Split-Brain chúng ta cần quan tâm thông số ‘discovery.zen.minimum_master_nodes‘ , như đã đề cập ở phần quá trình bầu chọn Master Node. Chúng ta sẽ tìm hiểu thử nếu để giá trị này là mặc định (1) chuyện gì sẽ xảy ra.
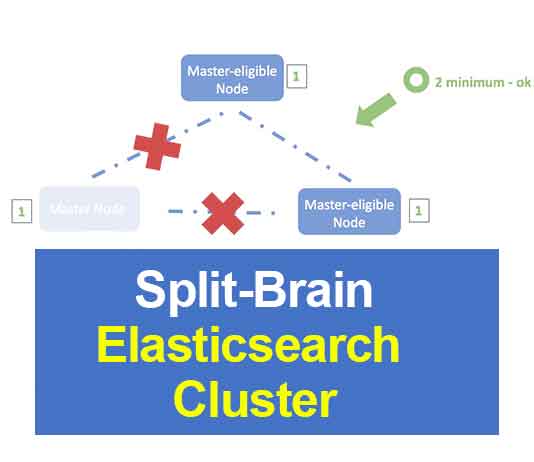
- Với giá trị ‘minimum_master_nodes‘ là 1 : các Master-eligible Node có thể tự bầu chọn chính nó làm Master Node trong trường hợp sự cố mạng có vấn đề. Do nó được quy định chỉ cần số lượng thấp nhất 1 Master-eligible Node là đã có thể bắt đầu quá trình bầu chọn Master Node mới nếu Master Node có sự cố. Do nó đã là 1 Master-eligible rồi, nên nó cứ tự xử và sự cố ‘Split-brain‘ phát sinh từ đây. Cả 2 Node này sẽ không bao giờ quay lại cụm cluster đầu tiên nếu không có sự khởi động lại một trong hai Node để bắt đầu mới quá trình bầu chọn hay tham gia cụm Cluster .
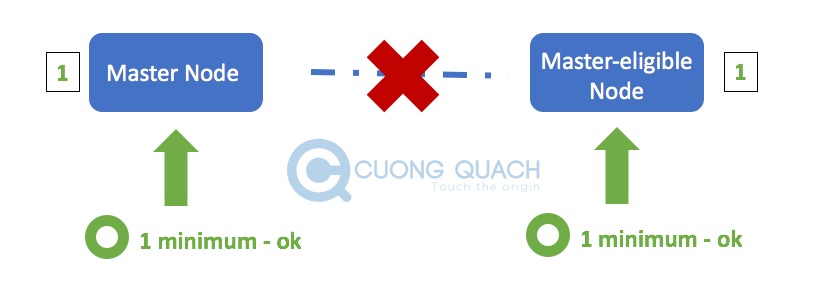
- Với giá trị ‘minimum_master_nodes‘ là 2 : các Master-eligible Node cần nhìn thấy tối thiểu 2 Master-eligible trong mạng (bao gồm cả nó) để có thể bắt đầu quá trình bầu chọn Master Node mới. Theo hình thì bạn thấy 1 bên trái sẽ không thể thấy đủ 2 Master-eligible Node cần thiết, nên từ cơ chế Master Node sẽ chuyển sang cơ chế Non-Master Node. Còn bên phải cả 2 Master-eligible Node đều thấy nhau nên thoả mãn điều kiện để bầu chọn Master Node mới.
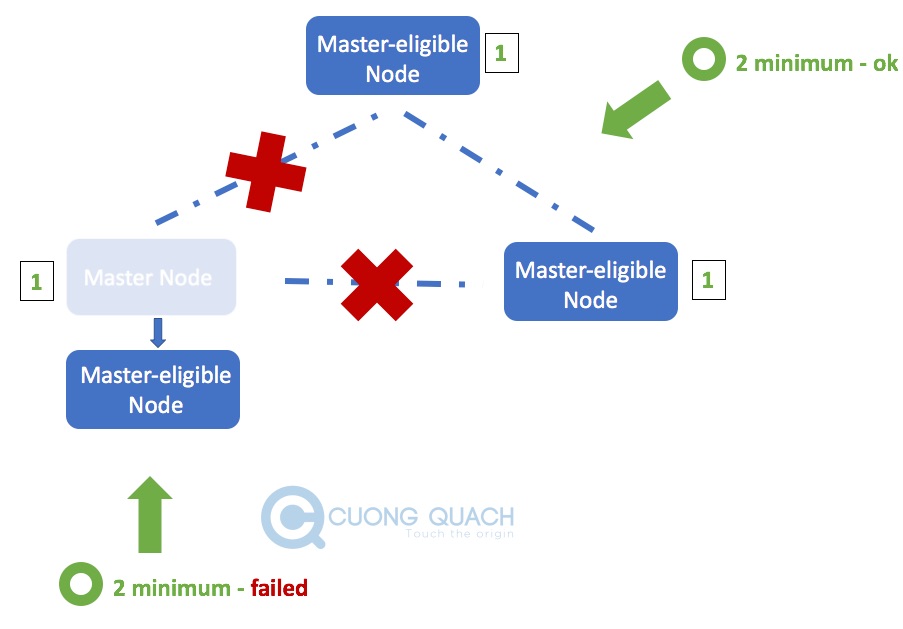
Cấu hình số lượng Master-eligible Node tối thiểu
Giá trị ‘minimum_master_nodes‘ cực kì quan trọng cho tính sẵn sàng của hệ thống Elasticsearch Cluster khi đảm bảo Master Node luôn chạy. Con số tối ưu Minimum Master-eligible Node là 3 . Vì nếu cấu hình nhiều Master-eligible Node sẵn sàng, sẽ làm tăng số lượng Node cần phải kiểm tra trạng thái là không cần thiết.
Giá trị ‘minimum_master_nodes‘ sẽ nói với Elasticsearch không được thực hiện quá trình bầu chọn Master Node nếu không có đủ số lượng Master-eligible Node được nhìn thấy nhau bởi các Master-eligible Node (các server sẵn sàng trở thành Master Node).
Hãy luôn sử dụng công thức ‘quorum‘ mà Elasticsearch khuyến cáo để tính toán thông số cấu hình ‘minimum_master_nodes‘ :
(number of master-eligible nodes / 2) + 1
Cấu hình này có thể cấu hình trong file ‘elasticsearch.yml‘ :
discovery.zen.minimum_master_nodes: 2
Cấu hình này có thể linh động cập nhật qua API Elasticsearch nhưng nó không mang tính vĩnh viễn như khi cấu hình trong file .
Cấu hình chuẩn Master Node
Đây là cấu hình chuẩn thường được ứng dụng để đảm bảo số lượng Master-eligible Node và quá trình bầu chọn Master Node an toàn tránh sự cố ‘Split-brain‘ phát sinh.
discovery.zen.fd.ping_timeout: 10s discovery.zen.minimum_master_nodes: 2 discovery.zen.ping.unicast.hosts: ["master_node_01″,"master_node_02″,"master_node_03″]
Chú thích:
- fd.ping_timeout: quy định thời gian kiểm tra một Node .
- minimum_master_nodes: số lượng Master-eligible Node tối thiểu cần hiện hữu để bắt đầu quá trình bầu chọn Master Node.
- ping.unicast.hosts: danh sách các Master-eligible Node (các Node sẵn sàng trở thành Master Node).
Tổng kết
Vấn đề sự cố Split-Brain ảnh hưởng rất nghiêm trọng đến hoạt động của hệ thống Elasticsearch Cluster. Nên bạn cần nắm rõ Split-Brain để cấu hình ‘minimum_master_nodes‘ một cách hợp lý giúp hệ thống chạy tốt.
Nguồn: https://cuongquach.com






")


")
")

")
