")

")
")
Tìm hiểu về Elasticsearch Cluster – Cuongquach.com | Chúng ta cùng tiếp tục tìm hiểu nội dung về Elasticsearch mang tên Elasticsearch Cluster (cụm phân tán Elasticsearch). Một trong những nội dung rất quan trọng khi thiết kế mô hình vận hành ES cho hoạt động lưu trữ tìm kiếm log trên hệ thống production. Bạn cần nắm bắt được vai trò của các ES Node, cách ES Node giao tiếp với nhau, Topology ES Node chạy là gì,…. Cùng Cuongquach.com tìm hiểu về Elasticsearch Cluster nhé.
Có thể bạn quan tâm chủ đề khác
– Kiểm tra cấu hình khuôn mẫu Logstash Grok bằng công cụ online
– 5 lưu ý thường gặp khi sử dụng Filebeat gửi log
– Hướng dẫn tạo Document và quản lý Document trong Elasticsearch
– Tạo Index và Quản lý Index trong Elasticsearch
– Tìm hiểu dịch vụ Logstash trong hệ thống ELK Stack Logging
Contents
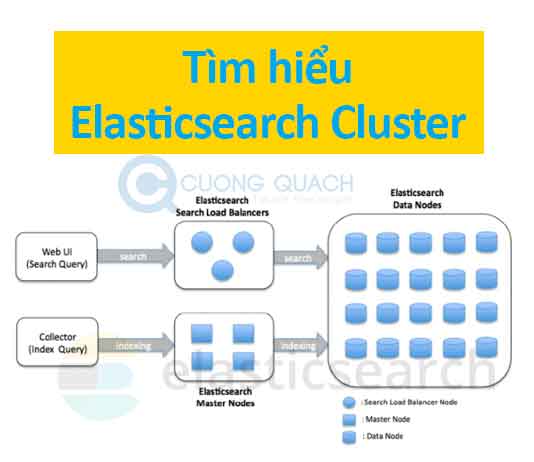
Một cụm phân tán ES Node (ES Cluster Node)
Khi bạn khởi chạy một máy chủ Elasticsearch, thì bạn đã khởi động một ES Node và chúng ta mặc định đã có một Cluster với duy nhất một Node đơn lẻ đang hoạt động. Khi mà bạn khởi động thêm một máy chủ Elasticsearch khác có cùng cấu hình ‘cluster.name‘ với Node ES ta đã khởi động ban đầu thì bạn bắt đầu có một cụm phân tán ES với 2 Node. Vậy nếu bạn khởi động nhiều máy chủ ES nữa cùng gia nhập Cluster ES thì hoàn toàn là chuyện đơn giản.
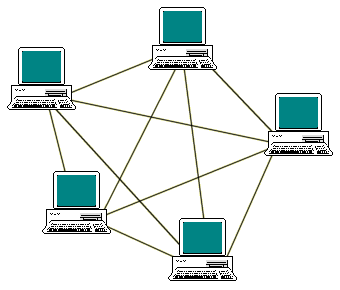
Mỗi Node trong cụm cluster có thể giao tiếp với các Node khác qua phương thức kĩ thuật riêng của Elasticsearch chạy giao thức TCP. Mô hình mà Cluster ES chạy là ‘mesh topology‘, toàn bộ các Node đều giao tiếp với nhau.
Vai trò của các ES Node
Mỗi Node ES trong một Cluster đều có thể đảm nhận các vai trò chức năng khác nhau đảm bảo mô hình hoạt động an toàn, chịu lỗi và tính sẵn sàng cao cho nhu cầu search/lưu trữ log.
File cấu hình vai trò ES Node nằm ở (nếu bạn cài qua package hoặc repository):
/etc/elasticsearch/elasticsearch.yml
Nội dung cấu hình Role ES Node
node.master: true/false node.data: true/false node.ingest: true/false search.remote.connect: true/false
Chú thích:
- node.master: kích hoạt (true) vai trò Master ES Node.
- node.data: kích hoạt (true) vai trò Data ES Node.
- node.ingest: kích hoạt (true) vai trò Ingest ES Node.
- search.remote.connect: kích hoạt (true) khả năng search giữa các cụm cluster.
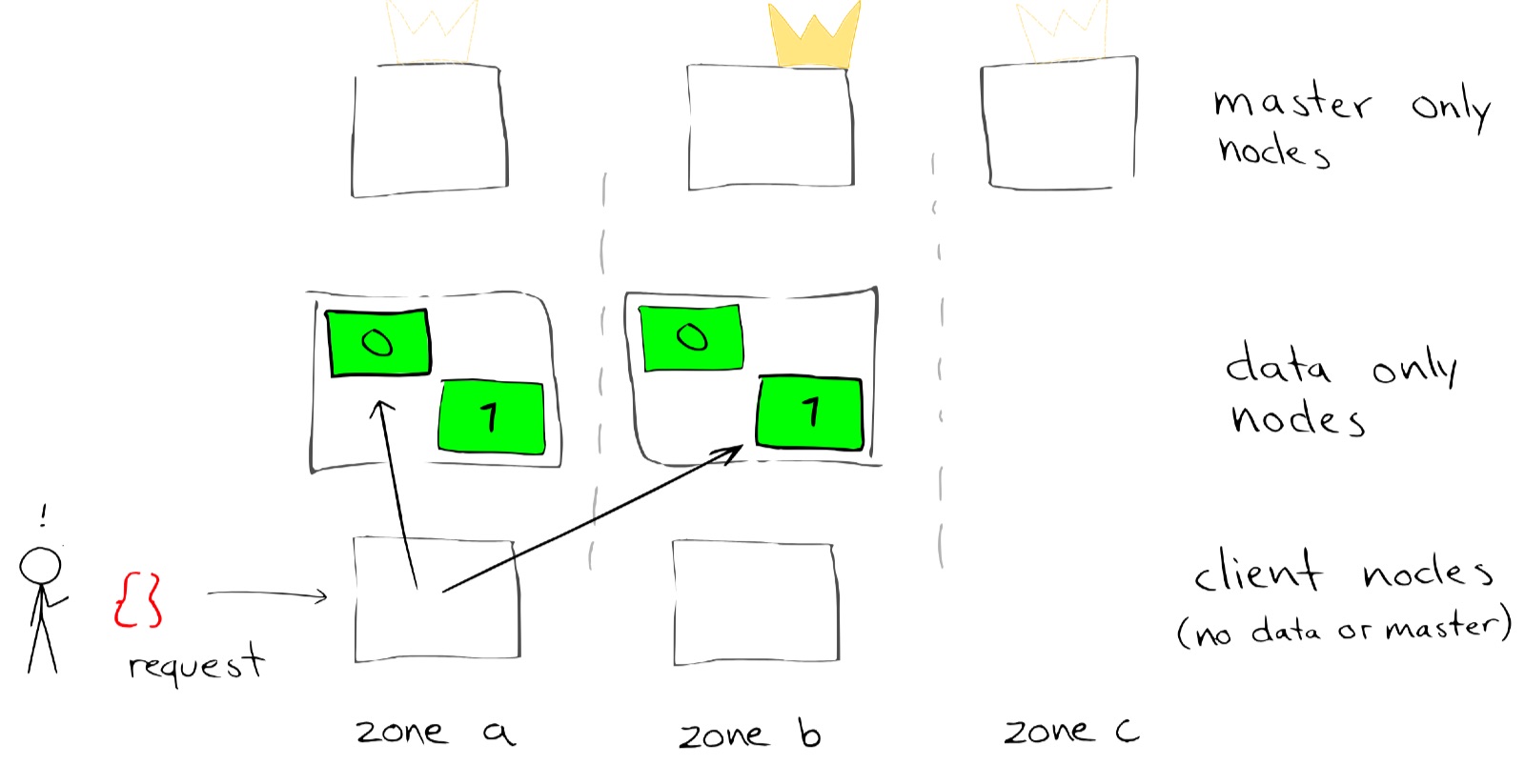
+ Master Node
Master Node chịu trách nhiệm cho các hoạt động quản lý tạo, xoá Index, tái sắp xếp shard, thêm hoặc xoá một Node Elasticsearch khỏi Cluster. Bên cạnh đó, nếu trạng thái cluster của ES có sự thay đổi thì Master Node sẽ broadcast các sự thay đổi đến toàn bộ các node hiện hành trong hệ thống cluster.
Kế đến bạn cần lưu ý là chỉ có một Master Node hoạt động trong một thời điểm của hệ thống Cluster, bạn hoàn toàn có thể cấu hình backup Master Node với một node dự trù riêng.
Trong một hệ thống ES Cluster chạy production, thường chúng ta sẽ dựng 1 con server chỉ để chạy Master Node , không xử lý các truy vấn từ client.
Mặc định khi cài đặt Elasticsearch mới toanh thì, một Node sẽ vừa là Master Node vừa là Data Node.
node.master: true node.data: true node.ingest: false search.remote.connect: false
Để cấu hình máy chủ chỉ chạy chức năng Master Node ES:
node.master: true node.data: false node.ingest: false search.remote.connect: false
+ Data Node
Data Node chịu trách nhiệm cho việc lưu trữ dữ liệu ở các shard và thực hiện các hoạt động liên quan đến dữ liệu như CRUD : tạo, đọc, cập nhật, xoá, tìm kiếm,… Bạn hoàn toàn có thể có nhiều Data Node trong một cụm ES Cluster. Nếu mà một Data Node chết hoặc dùng hoạt động thì cụm cluster vẫn tiếp tục vận hành và tiến hành tổ chức lại các shard Index trên các node khác.
Để cấu hình Data Node ES:
node.master: false node.data: true node.ingest: false search.remote.connect: false
+ Client Node/Coordinating Node
Client Node chịu trách nhiệm cho việc điều hướng các truy vấn hoặc cân bằng tải các truy vấn tuỳ theo chức năng đến các Master Node hoặc Data Node. Có thể mường tượng Client Node có công năng như 1 con ‘router’ vậy.
Một Client Node sẽ không lưu trữ bất kì dữ liệu nào và nó cũng không thể trở thành Master Node.
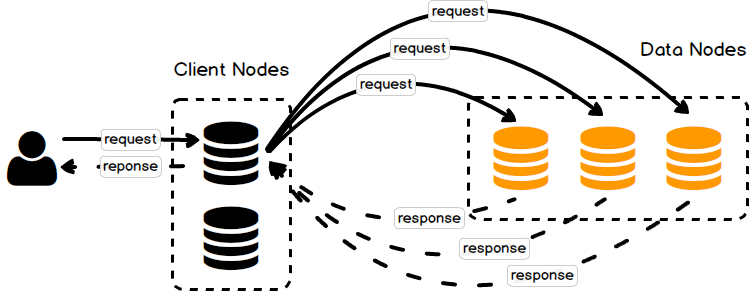
Hình minh hoạ Node Client 1: client node điều hướng các truy vấn liên quan đến dữ liệu (CRUD) đến các Data Node trong cụm cluster.
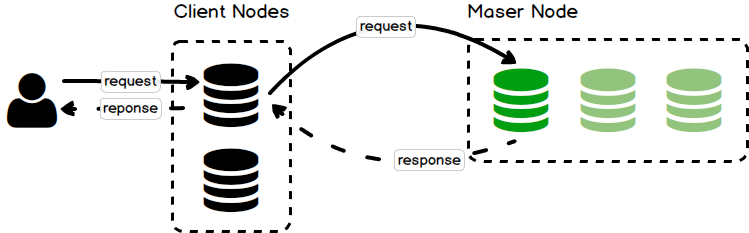
Hình minh hoạ Node Client 2: client node điều hướng các truy vấn liên quan đến cluster về các Master Node.
Để cấu hình Client Node ES:
node.master: false node.data: false node.ingest: false search.remote.connect: false
+ Ingest Node
Ingest Node sẽ hỗ trợ bạn thực hiện hoạt động xử lý các documents trước khi quá trình index bắt đầu.
Để cấu hình Ingest Node ES:
node.master: false node.data: false node.ingest: true search.remote.connect: false
+ Tribe Node
Hoạt động với chức năng đặc biệt như một Client Node có khả năng giao tiếp với rất nhiều cụm ES Cluster khác nhau để thực hiện các thao tác tìm kiếm hoặc hành vi liên quan đến dữ liệu.
Thêm một ES Node vào ES Cluster
Khi chúng ta thêm một ES Node vào cụm phân tán (cluster) ES thì Node mới thêm đó sẽ tiến hành ping toàn bộ các node đang chạy trong cluster để tìm ra Master Node. Một khi Master Node đã được tìm thấy, ES Node mới sẽ hỏi Master xin phép được nhập vào cụm ES Cluster đang chạy bằng request xin phép. Khi mà Master Node đồng ý cho phép ES Node mới tham gia vào cluster thì Master Node sẽ thông báo với toàn bộ các Node khác trong cụm cluster về sự hiện diện của Node mới. Cuối cùng ES Node mới có thể kết nối giao tiếp với toàn bộ các ES Node khác.
Khi mà ES Node mới được gia nhập cluster thành công, thì Master Node sẽ tiến hành tái sắp xếp dữ liệu giữa các Node. Việc tái sắp xếp này thường diễn ra khi bạn tạo các Index mới hoặc chủ động tái sắp xếp (reallocate) dữ liệu cho một Index (re-index).
Loại bỏ một ES Node khỏi ES Cluster
Nếu chúng ta dừng một ES node hoặc một Node trong cụm ES Cluster dừng hoạt động ở một thời điểm thì Master Node sẽ loại bỏ Node đó khỏi Cluster. Master Node sẽ tiến hành hoạt động tái sắp xếp dữ liệu trên các Node khác nếu Node bị loại bỏ là một Data Node.
Mà làm thế nào mà Master Node biết được Node nào trong cụm cluster còn hoạt động ?! Đơn giản là Master Node sử dụng cơ chế kĩ thuật nhận biết lỗi riêng như bắn tín hiệu đến toàn bộ các node trong cụm và kiểm tra xem các Node còn sống không.
Vậy trong trường hợp Master Node chết thì sao ? Hiển nhiên chúng ta thường sẽ có 1 Master Node và thường có 2 Backup Master Node. Các Node trong cùng cụm phân tán sẽ sử dụng cơ chế kĩ thuật nhận diện lỗi hệ thống ở các Node trong cùng ES Cluster, ví dụ chúng ping Master Node để kiểm tra khả năng sống còn. Nếu Master Node chết, thì Master Node backup khác sẽ được lựa chọn trở thành Master Node mới trong vòng vài giây.
Tổng kết
Vậy là bạn đã biết qua tổng quan về Elasticsearch Cluster (cụm phân tán ES) cùng vai trò của các ES Node. Bạn cần nắm vững để có thể tiếp tục các bài viết liên quan như : xây dựng mô hình Master Node hợp lý, cân bằng tải trong Elasticsearch Cluster, cấu hình Elasticsearch Cluster,..
Nguồn: https://cuongquach.com/






")
")
 – TTTH ĐH KHTN – Download ebook")

")

