")

")
")
Tìm hiểu cơ chế Healthcheck Readiness và Liveness trong Kubernetes – Cuongquach.com | Hệ thống phân tán có thể khó quản lý. Một lý do lớn là có nhiều bộ phận (dịch vụ) chuyển động trong kiến trúc này mà tất cả cần phải làm việc để hệ thống hoạt động trơn tru. Nếu một phần nhỏ bị hỏng, hệ thống phải phát hiện ra nó, định tuyến xung quanh nó và sửa nó. Và tất cả điều này cần phải được thực hiện tự động!
Kiểm tra sức khỏe (health check) là một cách đơn giản để cho hệ thống biết liệu một ứng dụng dịch vụ của bạn có hoạt động đúng đắn hay không hoạt động. Nếu một phiên bản của ứng dụng của bạn không hoạt động, thì các dịch vụ khác không nên truy cập vào nó hoặc gửi yêu cầu đến nó. Thay vào đó, các yêu cầu nên được gửi đến một phiên bản khác của ứng dụng đã sẵn sàng hoặc thử lại sau đó. Hệ thống cũng sẽ cố đưa ứng dụng của bạn trở lại trạng thái khỏe mạnh.
Theo mặc định, Kubernetes bắt đầu gửi lưu lượng đến một nhóm Container (deployment/replicaset) khi tất cả các container bên trong nhóm bắt đầu và khởi động lại các container khi chúng gặp sự cố. Mặc dù điều này có thể rất tốt khi bạn bắt đầu, nhưng bạn có thể làm cho việc triển khai của mình mạnh mẽ hơn bằng cách tạo các hình thức kiểm tra sức khỏe tùy chỉnh đối với dịch vụ container của bạn. May mắn thay, Kubernetes thực hiện điều này tương đối đơn giản với: Liveness và Readiness

Contents
Cơ chế kiểm tra Liveness Probe
Cơ chế kiểm tra container Liveness giúp Kubernetes biết là ứng dụng container của bạn đang sống hay chết (hay không hoạt động đúng chức năng). Nếu mà ứng dụng container của bạn còn sống, thì Kubernetes sẽ giữ nguyên không đụng chạm gì nó. Còn nếu ứng dụng của bạn chết hoặc không hoạt động đúng chức năng mong muốn thì Kubernetes sẽ tắt Pod đó đi và khởi động lại một Pod container mới.
Hãy cứ tưởng tượng, bạn có một web service vì lý do nào đấy mà crash hoặc function xử lý sai chức năng, cũng có khi do bị treo mà không hề exit process để tự tắt ứng dụng container. Thì lúc này tiến trình đó vẫn chạy, nhưng bản chất không hoạt động như mong muốn và Kubernetes cứ nghĩ là Pod Container đó đang chạy tốt và gửi các request đến cho Pod Container này xử lý và rồi lỗi ơi là lỗi phát sinh.
Thường chúng ta sẽ thấy các web service được yêu cầu phải tích hợp một endpoint url health check ví dụ như “/health“. Endpoint url này khi được Kubernetes hay bất kì chương trình kiểm tra health check khác truy cập thì phải thực hiện các logic kiểm tra đúng đắn như có thể query database , có thể kết nối cache database,… để biết là ứng dụng có thực sự hoạt động đúng hay không ?
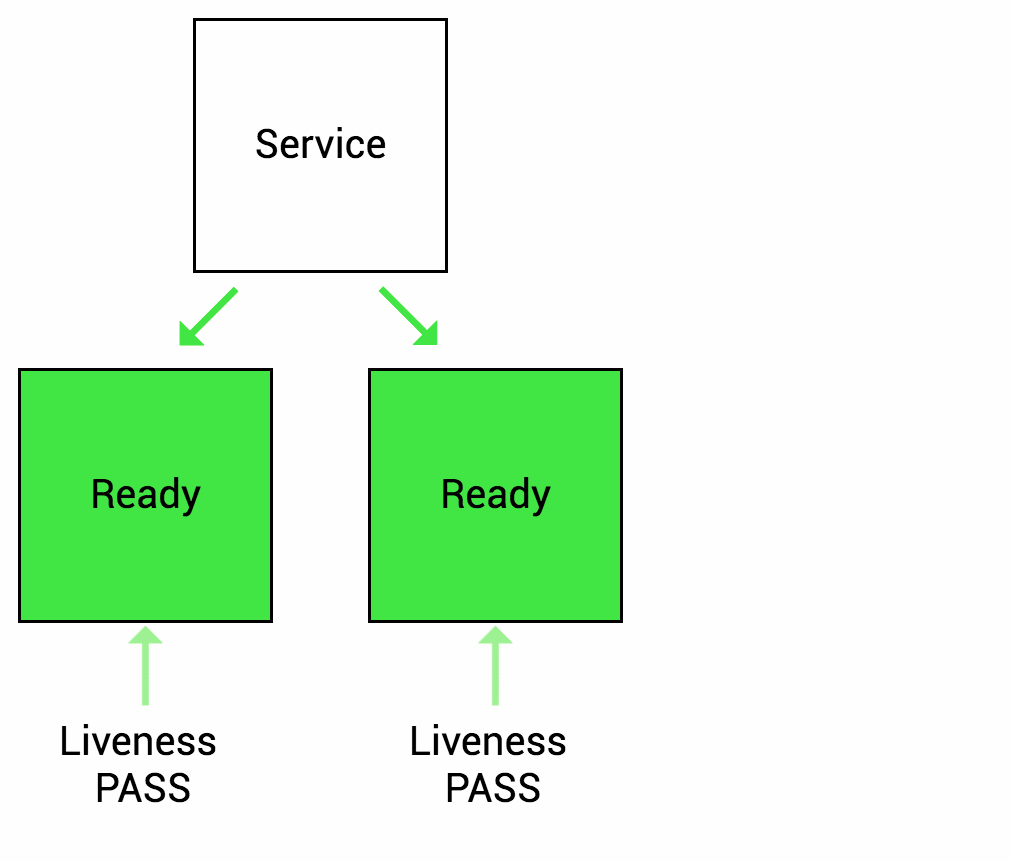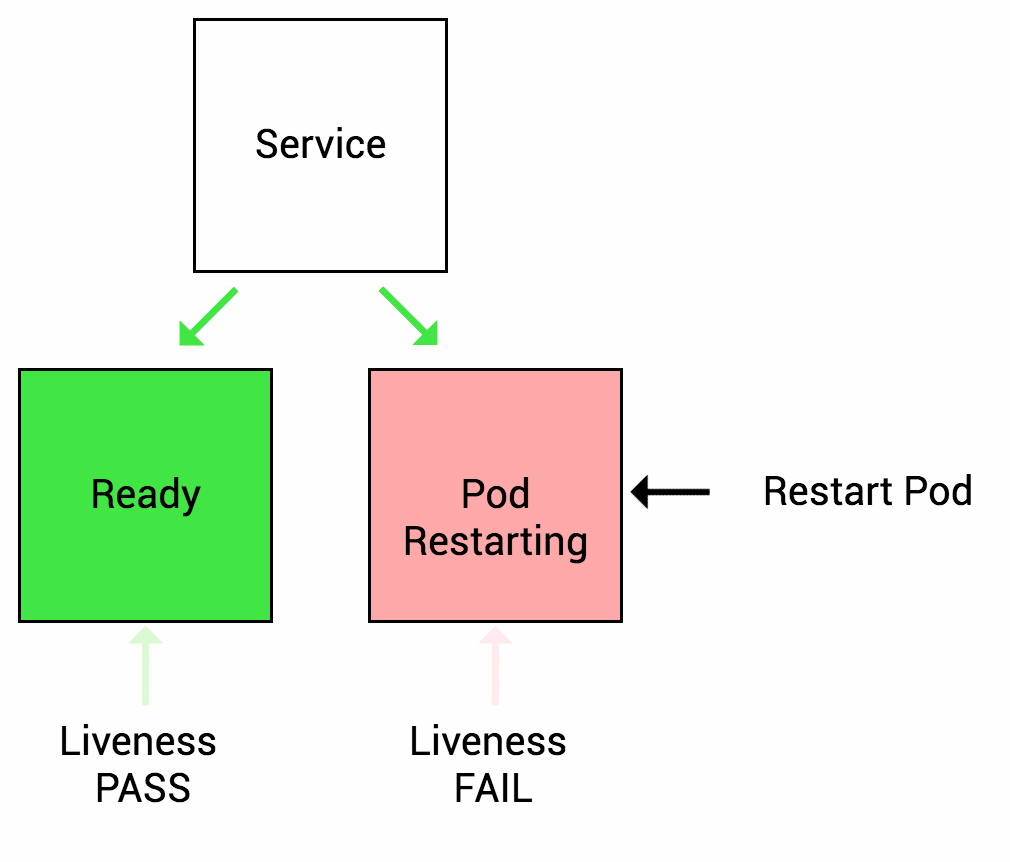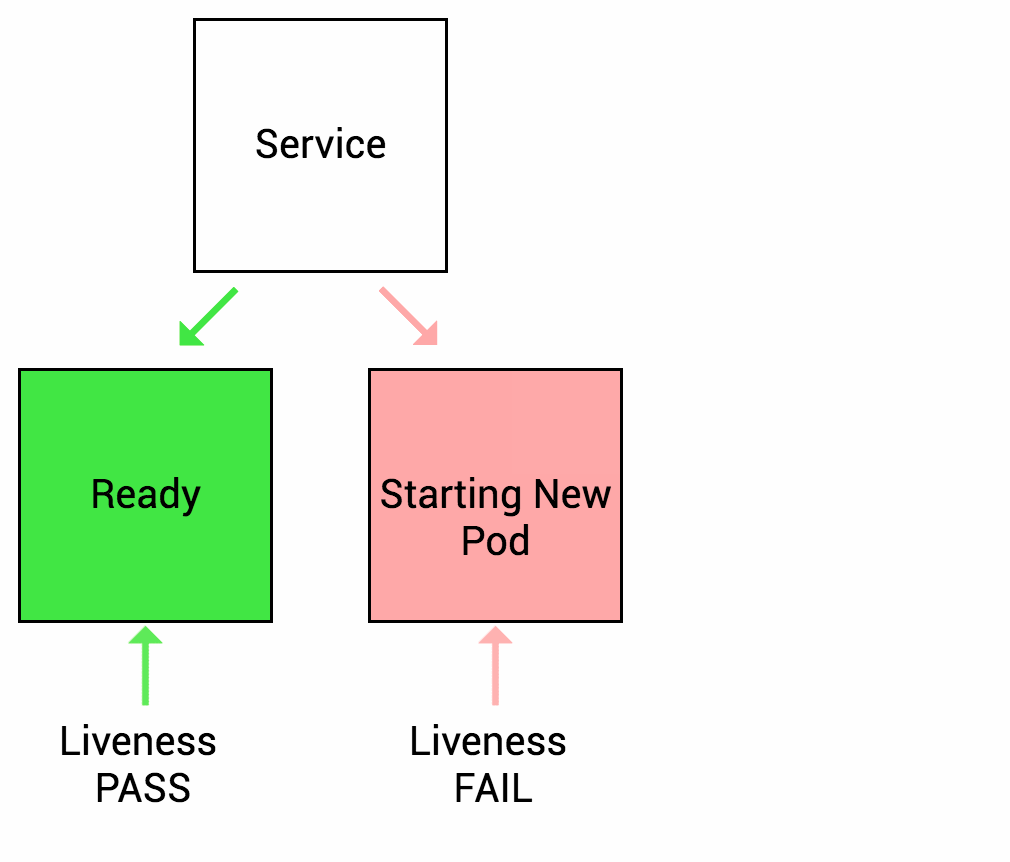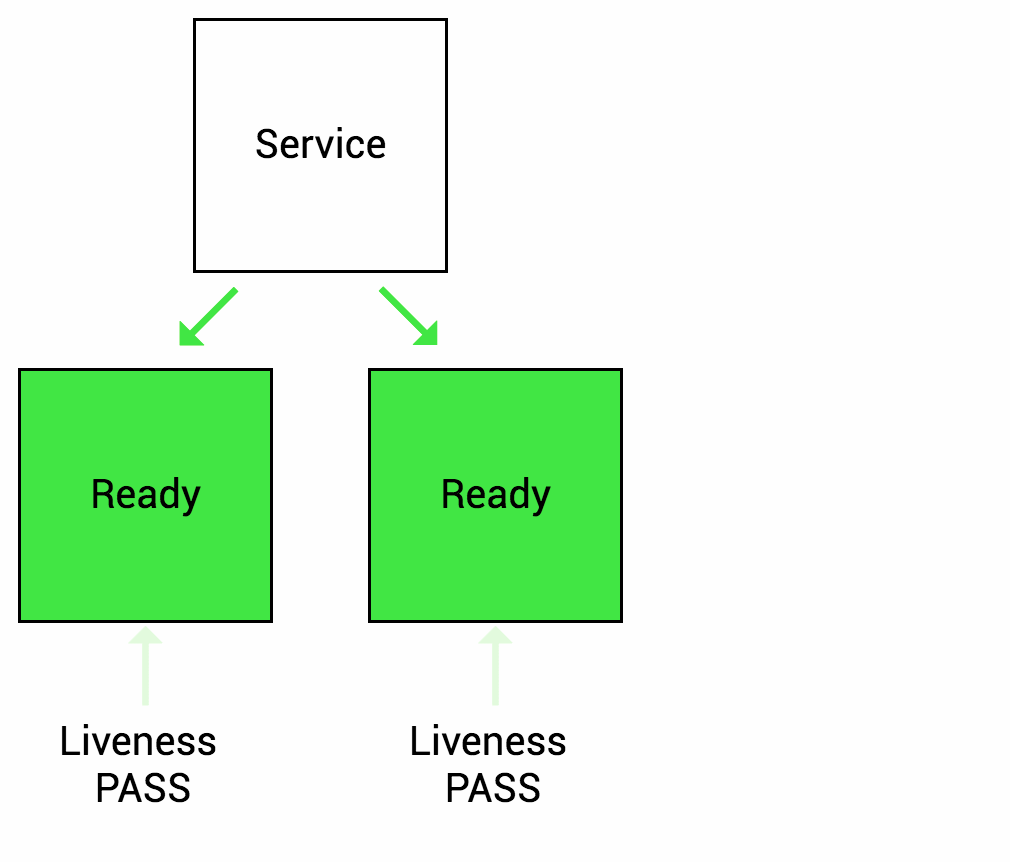
Hình dưới minh hoạ khoảng thời gian mặc định khi kiểm tra Liveness với ứng dụng container trước khi restart pod container đó.
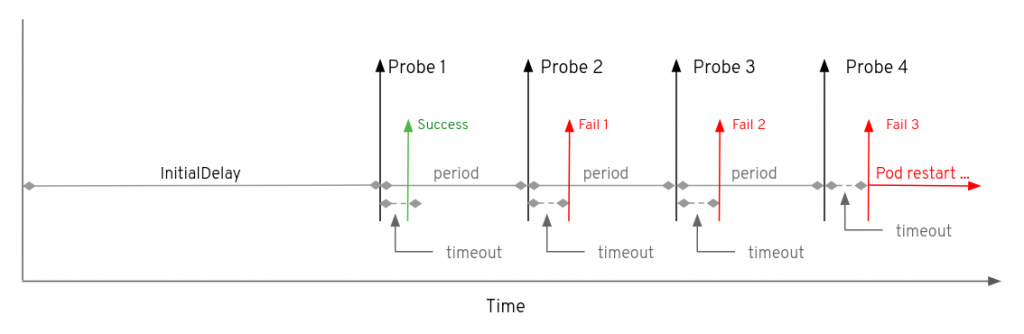
Cơ chế kiểm tra Readiness Probe
Đôi khi ứng dụng web service trong container của bạn sẽ cần một khoảng thời gian đầu khởi động không thể tiếp nhận xử lý các lưu lượng request gửi tới. Ví dụ như:
- Ứng dụng của bạn cần thời gian để load dữ liệu này.
- Ứng dụng của bạn load cấu hình từ một nơi nào đó khác.
- Cũng có thể ứng dụng của bạn liên kết với một dịch vụ ngoài khác để thiết lập các nội dung riêng biệt.
Thì trong suốt quá trình khởi động này, ứng dụng web service container sẽ chưa sẵn sàng xử lý request mới. Trong khi Kubernetes mặc định sẽ đẩy lưu lượng request xuống Pod vừa khởi tạo nếu Pod ở trạng thái Success. Vậy chúng ta sẽ cần “Rediness probe” là cơ chế giúp Kubernetes kiểm tra xem ứng dụng container của bạn đã sẵn sàng tiếp nhận xử lý request chưa (thường ít áp dụng cho các dạng service worker).
Nếu pod của bạn có cấu hình Readiness và không thoả mãn được các lần kiểm tra từ Kubernetes, thì Kubernetes sẽ không đẩy lưu lượng traffic xuống pod container của bạn. Tất nhiên thì lưu lượng request đó sẽ đi thông qua dịch vụ Kubernetes Service (service endpoint). Pod IP sẽ bị loại khỏi danh sách endpoint service nếu không thoả mãn Readiness check.
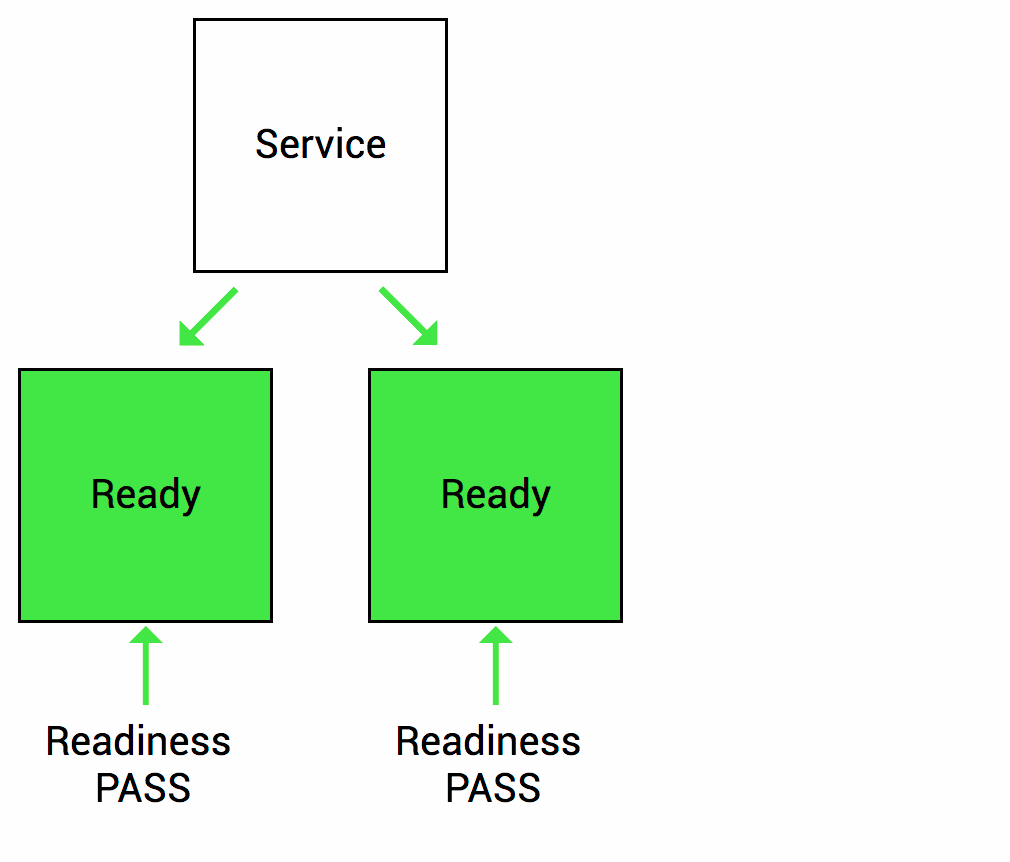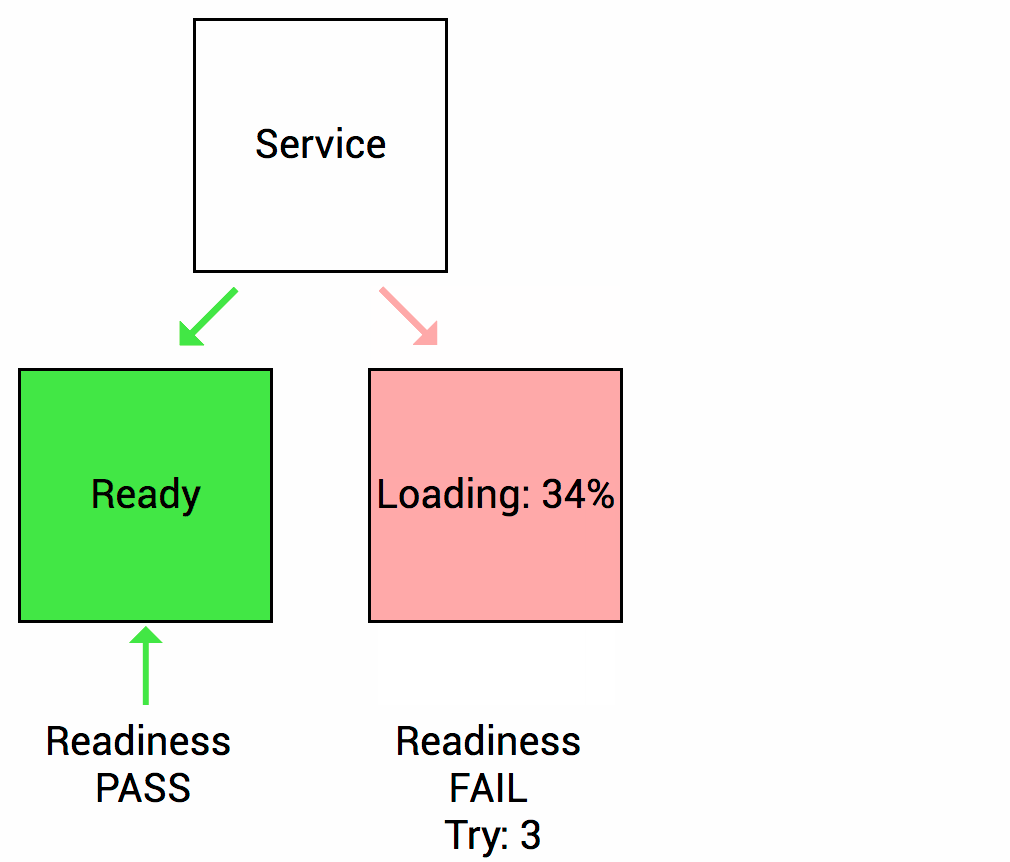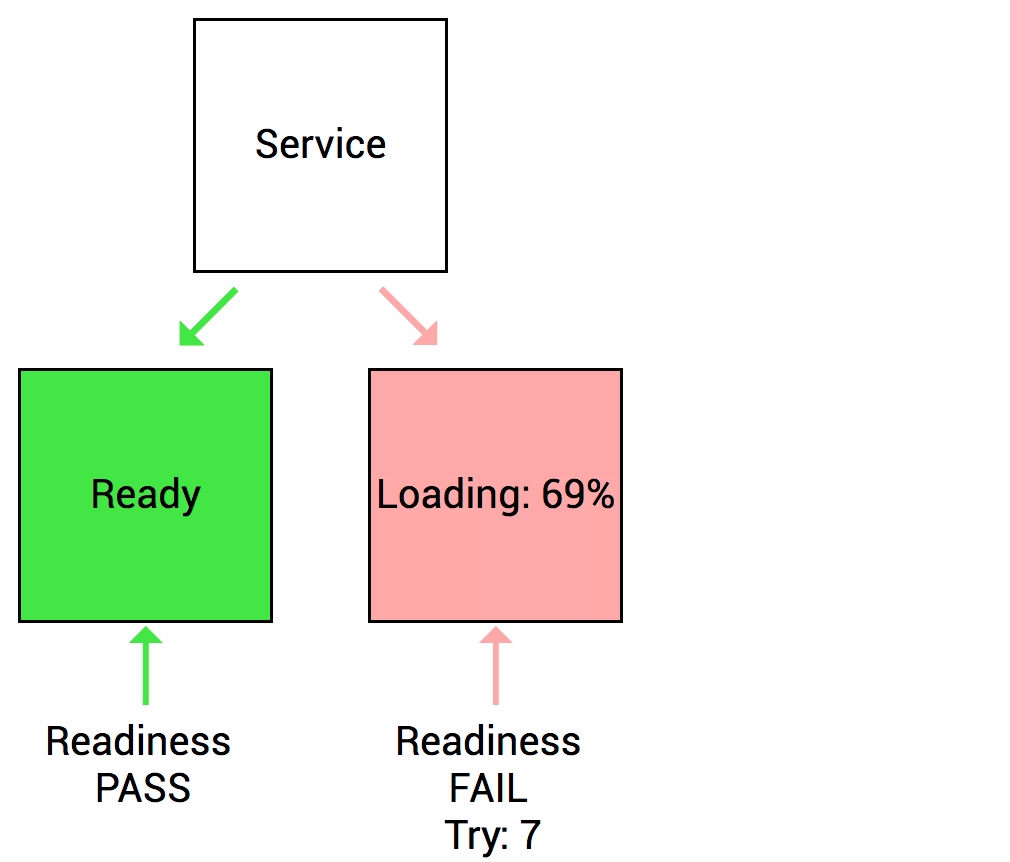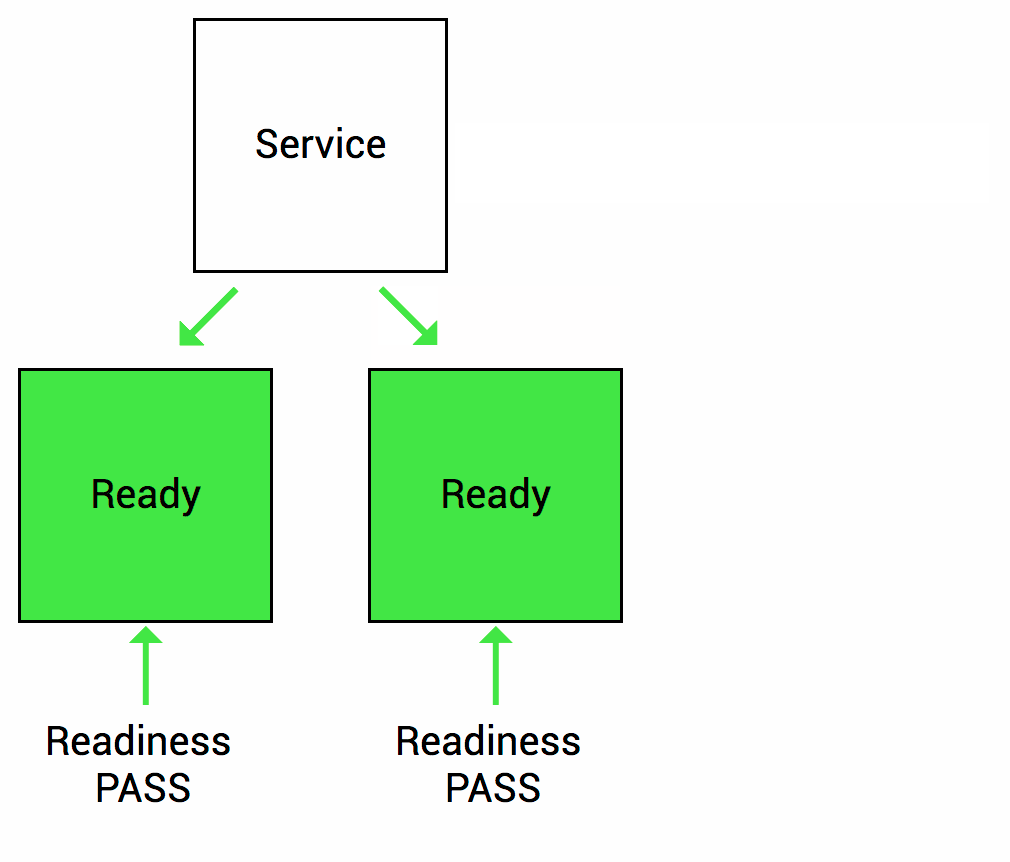
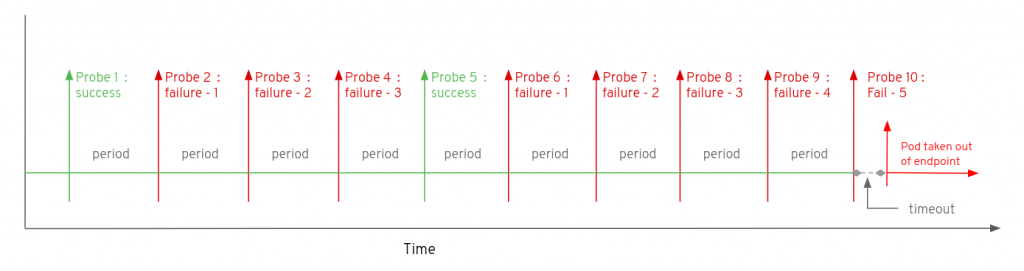
Hình dưới minh hoạ khoảng thời gian mặc định khi kiểm tra Readiness với ứng dụng container trước khi restart pod container đó.
Các cơ chế kiểm tra health check Liveness/Readiness
- HTTP probe: kubelet sẽ gửi HTTP request đến host (mặc định sẽ là Pod Ip) và url mà bạn chỉ định. Nếu mà dịch vụ web service của bạn phản hồi HTTP Status 200 hay 300 thì tức ứng dụng container của bạn vẫn hoạt động tốt. Ngược lại thì là ứng dụng container của bạn chưa sẵn sàng phục vụ request hoặc đang bị lỗi cần restart lại.
- TCP probe: kubelet sẽ thử khởi tạo connection TCP đến port quy định. Nếu khởi tạo thành công thì ứng dụng container của bạn đã sẵn sàng hoặc vẫn còn hoạt động tốt.
- Command: sẽ thực hiện chương trình command hoặc script bạn chỉ định. Exit code của command cần trả về là 0 thì là thành công.
Cấu hình mẫu với các cơ chế kiểm tra Liveness/Readiness
Cấu hình thì khá là dễ hiểu nên không cần đào sâu nhiều phần này, các bạn hiểu được concept là quan trọng nhất. Các cấu hình chi tiết có thể tham khảo ở đây: Configure Liveness, Readiness Probes
Nội dung và cách cấu hình của Liveness và Readiness là giống nhau, chỉ khác mỗi khai báo loại healthcheck nào sẽ được áp dụng thôi “livenessProbe” hay “readinessProbe“.
+ Method Command Probe
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
+ Method HTTP Probe
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
+ Method TCP Probe
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
+ Liveness và Readiness đồng thời
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
Một số cấu hình lưu ý Liveness/Readiness Probe
Một số trường cấu hình bạn nên nắm qua ý nghĩa của nó khi sử dụng cấu hình Liveness/Readiness :
- initialDelaySeconds: thời gian (giây) sau khi container khởi động thì sẽ bắt đầu các hoạt động kiểm tra liveness/readiness. Mặc định là 0 giây.
- periodSeconds: thời gian giữa các lần thực hiện kiểm tra liveness/readiness. Mặc định là 10 giây.
- timeoutSeconds: thời gian timeout của các hoạt động kiểm tra liveness/readiness. Mặc định là 1 giây.
- successThreshold: số lần thực hiện kiểm tra liveness/readiness trả kết quả tốt thì được coi là thành công cho việc kiểm tra. Mặc định là 1 .
- failureThreshold: số lần thực hiện kiểm tra liveness/readiness trả kết quả xấu thì được coi là thất bại cho việc kiểm tra. Mặc định là 3.
Lưu ý
Readiness và Liveness có thể sử dụng đồng thời cho cùng 1 pod container, để đảm bảo traffic đến các pod container đó khi đã sẵn sàng xử lý. Và container đó sẽ được khởi động lại khi bị lỗi.
Nguồn: https://cuongquach.com/

")

")

")
")
")
")




